Welcome to the Adversarial Robustness Toolbox¶

Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to evaluate, defend, certify and verify Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, generation, certification, etc.).
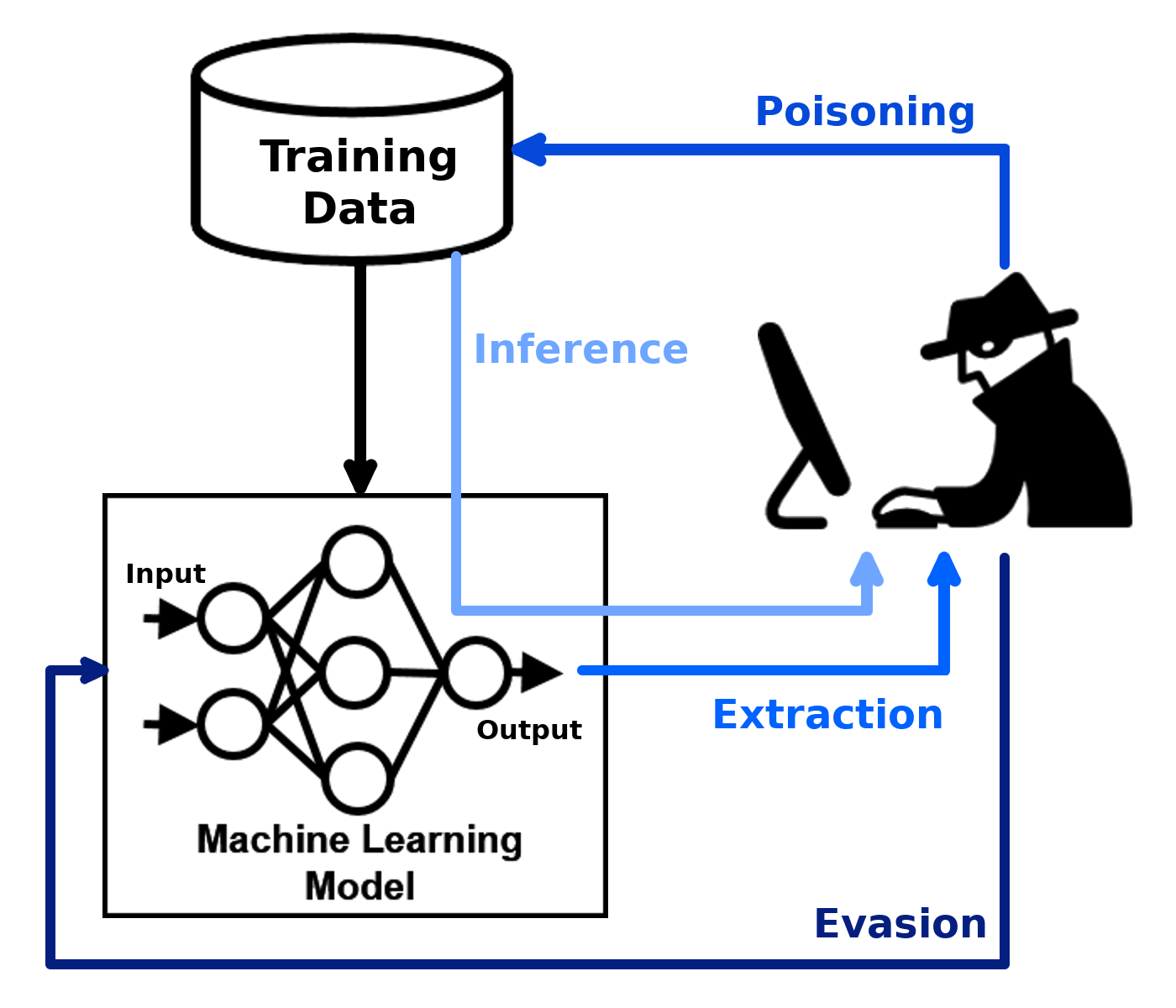
The code of ART is on GitHub and the Wiki contains overviews of implemented attacks, defences and metrics.
The library is under continuous development. Feedback, bug reports and contributions are very welcome!
Supported Machine Learning Libraries¶
TensorFlow (v1 and v2) (https://www.tensorflow.org)
Keras (https://www.keras.io)
PyTorch (https://www.pytorch.org)
MXNet (https://mxnet.apache.org)
Scikit-learn (https://www.scikit-learn.org)
XGBoost (https://www.xgboost.ai)
LightGBM (https://lightgbm.readthedocs.io)
CatBoost (https://www.catboost.ai)
Modules
art.attacksart.attacks.evasion- Adversarial Patch
- Adversarial Patch - Numpy
- Adversarial Patch - PyTorch
- Adversarial Patch - TensorFlowV2
- Adversarial Texture - PyTorch
- Auto Attack
- Auto Projected Gradient Descent (Auto-PGD)
- Auto Conjugate Gradient (Auto-CG)
- Boundary Attack / Decision-Based Attack
- Brendel and Bethge Attack
- Carlini and Wagner L_0 Attack
- Carlini and Wagner L_2 Attack
- Carlini and Wagner L_inf Attack
- Carlini and Wagner ASR Attack
- Composite Adversarial Attack - PyTorch
- Decision Tree Attack
- DeepFool
- DPatch
- RobustDPatch
- Elastic Net Attack
- Fast Gradient Method (FGM)
- Feature Adversaries - Numpy
- Feature Adversaries - PyTorch
- Feature Adversaries - TensorFlow
- Frame Saliency Attack
- Geometric Decision Based Attack
- GRAPHITE - Blackbox
- GRAPHITE - Whitebox - PyTorch
- High Confidence Low Uncertainty Attack
- HopSkipJump Attack
- Imperceptible ASR Attack
- Imperceptible ASR Attack - PyTorch
- Basic Iterative Method (BIM)
- Projected Gradient Descent (PGD)
- Projected Gradient Descent (PGD) - Numpy
- Projected Gradient Descent (PGD) - PyTorch
- Projected Gradient Descent (PGD) - TensorFlowV2
- LaserAttack
- LowProFool
- NewtonFool
- Malware Gradient Descent - TensorFlow
- Over The Air Flickering Attack - PyTorch
- PixelAttack
- ThresholdAttack
- Jacobian Saliency Map Attack (JSMA)
- Shadow Attack
- ShapeShifter Attack
- Sign-OPT Attack
- Simple Black-box Adversarial Attack
- Spatial Transformations Attack
- Square Attack
- Targeted Universal Perturbation Attack
- Universal Perturbation Attack
- Virtual Adversarial Method
- Wasserstein Attack
- Zeroth-Order Optimization (ZOO) Attack
art.attacks.extractionart.attacks.inference.attribute_inferenceart.attacks.inference.membership_inferenceart.attacks.inference.model_inversionart.attacks.inference.reconstructionart.attacks.poisoningart.defencesart.defences.detector.evasionart.defences.detector.poisonart.defences.postprocessorart.defences.preprocessor- Base Class Preprocessor
- CutMix
- CutMix - PyTorch
- CutMix - TensorFlowV2
- Cutout
- Cutout - PyTorch
- Cutout - TensorFlowV2
- Feature Squeezing
- Gaussian Data Augmentation
- InverseGAN
- DefenseGAN
- JPEG Compression
- Label Smoothing
- Mixup
- Mixup - PyTorch
- Mixup - TensorFlowV2
- Mp3 Compression
- PixelDefend
- Resample
- Spatial Smoothing
- Spatial Smoothing - PyTorch
- Spatial Smoothing - TensorFlow v2
- Thermometer Encoding
- Total Variance Minimization
- Video Compression
art.defences.trainer- Base Class Trainer
- Adversarial Training
- Adversarial Training Madry PGD
- Adversarial Training Adversarial Weight Perturbation (AWP) - PyTorch
- Adversarial Training Oracle Aligned Adversarial Training (OAAT) - PyTorch
- Adversarial Training TRADES - PyTorch
- Base Class Adversarial Training Fast is Better than Free
- Adversarial Training Fast is Better than Free - PyTorch
- Adversarial Training Certified - PyTorch
- Adversarial Training Certified Interval Bound Propagation - PyTorch
- DP - InstaHide Training
art.defences.transformer.evasionart.defences.transformer.poisoningart.estimatorsart.estimators.certificationart.estimators.certification.deep_zart.estimators.certification.intervalart.estimators.certification.randomized_smoothingart.estimators.classification- Mixin Base Class Classifier
- Mixin Base Class Class Gradients
- BlackBox Classifier
- BlackBox Classifier NeuralNetwork
- Deep Partition Aggregation Classifier
- Keras Classifier
- MXNet Classifier
- PyTorch Classifier
- Query-Efficient Black-box Gradient Estimation Classifier
- TensorFlow Classifier
- TensorFlow v2 Classifier
- Ensemble Classifier
- Scikit-learn Classifier Classifier
- GPy Gaussian Process Classifier
art.estimators.classification.scikitlearn- Base Class Scikit-learn
- Scikit-learn DecisionTreeClassifier Classifier
- Scikit-learn ExtraTreeClassifier Classifier
- Scikit-learn AdaBoostClassifier Classifier
- Scikit-learn BaggingClassifier Classifier
- Scikit-learn ExtraTreesClassifier Classifier
- Scikit-learn GradientBoostingClassifier Classifier
- Scikit-learn RandomForestClassifier Classifier
- Scikit-learn LogisticRegression Classifier
- Scikit-learn SVC Classifier
art.estimators.encodingart.estimators.ganart.estimators.generationart.estimators.object_detectionart.estimators.object_trackingart.estimators.poison_mitigationart.estimators.regressionart.estimators.regression.scikitlearnart.estimators.speech_recognitionart.experimental.estimatorsart.experimental.estimators.classificationart.evaluationsart.metricsart.preprocessingart.preprocessing.audioart.preprocessing.expectation_over_transformation- EOT Image Center Crop - PyTorch
- EOT Image Rotation - TensorFlow V2
- EOT Image Rotation - PyTorch
- EOT Brightness - PyTorch
- EOT Brightness - TensorFlow V2
- EOT Contrast - PyTorch
- EOT Contrast - TensorFlow V2
- EOT Gaussian Noise - PyTorch
- EOT Gaussian Noise - TensorFlow V2
- EOT Shot Noise - PyTorch
- EOT Shot Noise - TensorFlow V2
- EOT Zoom Blur - PyTorch
- EOT Zoom Blur - TensorFlow V2
art.preprocessing.standardisation_mean_stdart.data_generatorsart.exceptionsart.summary_writerart.utilstests.utils